
Metro кластеры СХД на базе ПО Open-E JovianDSS
 В предыдущей статье рассказывалось о кластеризации систем хранения данных (СХД), как о мере повышения доступности за счет отказоустойчивости. Там в типовых схемах интеграции СХД в корпоративную сеть были показаны лишь стандартные кластеры, размещаемые в пределах одной серверной. Программное обеспечение (ПО) Open-E JovianDSS может больше! Рассмотрим подробнее такую форму кластеризации СХД как Metro или «растянутые» кластеры, и, по ходу дела, сравним их со стандартными кластерами СХД.
В предыдущей статье рассказывалось о кластеризации систем хранения данных (СХД), как о мере повышения доступности за счет отказоустойчивости. Там в типовых схемах интеграции СХД в корпоративную сеть были показаны лишь стандартные кластеры, размещаемые в пределах одной серверной. Программное обеспечение (ПО) Open-E JovianDSS может больше! Рассмотрим подробнее такую форму кластеризации СХД как Metro или «растянутые» кластеры, и, по ходу дела, сравним их со стандартными кластерами СХД.
Мы разберем последовательно как устроены дисковые подсистемы и работа в режиме Active-Active, как организуются пути доступа клиентов к СХД и в чем особенности служебной коммутации в кластере, сравним схемы подключений и поговорим о «мозгах» Metro кластера, и, наконец, уточним какие лицензии нужны для кластеров СХД построенных на базе ПО Open-E JovianDSS.
На ИТ рынке Metro кластеры, как техническое решение, представлены в основном на базе дорогих проприетарных СХД корпоративного класса (например, MetroCluster от компании NetApp на СХД FAS), и поэтому мало доступны для многих компаний из-за высокой стоимости. ПО Open-E JovianDSS позволяет построить программно-определяемые СХД, как в виде стандартного, так и Metro кластера, причем, несмотря на то, что это решения корпоративного класса, такие Metro кластеры становятся доступными за счет их высочайшей ценовой эффективности.
Что такое Metro кластер
Название «Metro» для таких СХД кластеров происходит от греч. metropolis (главный город, столица) и связано с англ. термином Metropolitan Area Network (MAN) – общегородская вычислительная сеть, что в противовес LAN (Local Area Network) – локальная вычислительная сеть, подчеркивает большую протяженность городской сети. Кстати, и привычное нам название подземной железной дороги - «метро» или «метрополитен», тоже говорит о том, что это транспорт больших городов.
Metro кластер в Open-E JovianDSS – это территориально-распределенная отказоустойчивая СХД высокой доступности HA (High Availability). Фактически, это единая СХД, которая сильно «растянута» на две удаленные, иногда на десятки километров, части. В каждой из частей (их принято называть узлами) Metro кластера хранятся одинаковые данные, что позволяет не потерять их, даже в случае отказа одного из узлов единой СХД. Актуальность данных обеспечивается за счет зеркалирования дисковых хранилищ обоих узлов по сети Ethernet. Metro кластер Open-E JovianDSS позволяет объединить два офиса территориально-распределенной компании и получить защиту от катастроф, т.к. данные кластера СХД физически находятся в двух разных местах.
Дисковые хранилища в Metro и стандартном кластерах
В СХД кластере каждый узел должен иметь доступ ко всем дискам своих хранилищ. Посмотрим, в чем различия и особенности хранилищ в разных типах кластеров на Open-E JovianDSS:
 Картинка 1 Дисковые хранилища в Metro и стандартном кластерах
Картинка 1 Дисковые хранилища в Metro и стандартном кластерах
В стандартном кластере оба узла СХД подключаются к одному общему дисковому хранилищу по интерфейсу SAS. Схемы подключения узлов к дискам могут разниться – это может быть вариант с одной или несколькими внешними дисковыми полками JBOD или оба узла могут быть в одном корпусе с дисками, подключаемыми через общий backplane, но во всех случаях для работы в стандартном кластере каждый диск в хранилище должен иметь два пути доступа – по одному для каждого из узлов кластера. Таким образом, нужны двухпортовые диски SAS, а SATA диски с одним портом в стандартном СХД кластере JovianDSS работать не будут. Использование различных адаптеров-мультиплексоров для преобразования одного порта SATA диска в два порта как у диска SAS за счет периодического переключения, не рекомендуется, т.к. это может приводить к «чудесам» и нестабильной работе различного оборудования, что недопустимо в СХД корпоративного класса. Расстояние между узлами ограничено допустимой длиной внешних интерфейсных кабелей SAS (не рекомендуется более 6 метров, max 10 м) между узлами и общим дисковым хранилищем.
В Metro кластере СХД каждый узел тоже должен «видеть» все диски – как в своем дисковом хранилище, так и в хранилище удаленного узла. Доступ узла к своим локальным дискам не требует двух путей, а доступ к дискам другого узла осуществляется через Ethernet, поэтому можно использовать однопортовые недорогие диски SATA. Более того, на узлах Metro кластера допускается использование RAID контроллеров для управления локальными дисками, что в стандартном кластере осуществляется через хост адаптеры шины SAS. При выборе дисков стоит помнить, что именно из-за интерфейса SATA потоковая производительность у всех SATA SSD ограничена до 500-550 МБ/с. Часто бывает, что SSD с такими же микросхемами NAND, но с интерфейсом SAS способен выдать до 1000-1100 МБ/с, т.к. пропускная способность интерфейса SAS 3.0 в 2 раза выше, чем у SATA 3.0. В Metro кластере узлы для обмена данными в хранилищах связываются по Ethernet каналу, и поэтому расстояние между узлами уже не метры, а километры.
Пулы данных в Metro и стандартном кластерах
Пулы данных в дисковых хранилищах двух типах кластеров на JovianDSS формируются по-разному. В стандартном кластере пулы данных для файловой системы ZFS формируют из групп дисков в массивах с уровнями RAID-Z или mirror с различными уровнями отказоустойчивости: N-1, N-2, N-3, N-mirror. В Metro кластере пулы формируются из групп, состоящих из одной или нескольких зеркальных mirror пар дисков, причем каждое зеркало состоит из локальных дисков и из дисков хранилища удаленного узла.
 Картинка 2 Примеры формирования пулов данных в Metro и стандартном кластерах.
Картинка 2 Примеры формирования пулов данных в Metro и стандартном кластерах.
В файловой системе ZFS пулы данных формируются из одной или нескольких групп данных. Для каждой из групп данных выбирается уровень отказоустойчивости. Так, на Картинке 2 в Пуле 0 стандартного кластера выбран уровень RAID Z2 позволяющий сохранить целостность данных при потере до 2х дисков в каждой группе данных. Пул 1 Metro кластера сформирован из 2х дисковых зеркал, а Пул 0 для повышенной надежности и производительности сформирован из групп данных в виде 4х дисковых зеркал, состоящих из двух локальных и двух удаленных дисков. Для ускорения работы к ZFS пулам могут быть добавлены:
- кэширование записи – на Картинке 2 write cache. Кэширование данных в специальном журнале учета планируемых записей ZIL (ZFS Intent Log) с механизмом группировки несколько изменений данных в единую транзакцию для записи;
- кэширование чтения – на Картинке 2 read cache. Первичное кэширование данных ZFS осуществляет в кэше Adaptive Replacement Cache (ARC), хранимом в оперативной памяти RAM, а по мере заполнения ARC, данные переносятся в дисковый кэш второго уровня Level 2 ARC (L2ARC).
На самом деле ZIL и L2ARC не совсем верно называть кэшами записи и чтения – там применяются более сложные алгоритмы, чем просто кэширование, но это уже тема для отдельной статьи.
Для кэширования записи необходимо использовать отказоустойчивое зеркало минимум из двух SSD с высоким коэффициентом износостойкости DWPD (drive writes per day) порядка 10. Для Metro кластера зеркало write cache формируется из локального и удаленного SSD.
Для кэширования чтения можно использовать и зеркало и один SSD с небольшим DWPD порядка 1. На Картинке 2 диск для read cache Metro кластера является локальным у каждого узла, для него не нужно зеркало на другом узле и его данные не передаются по Ethernet каналу. В качестве диска для read cache можно использовать NVMe SSD работающие по шине PCI-E, что дает более высокую производительность. Зеркалирование SSD с интерфейсом NVMe не поддерживается.
Если группы данных пула сформированы только из SSD, то можно не использовать кэширование чтения и записи. Для каждого пула можно дополнительно назначить один или несколько дисков резерва - spare, они на Картинке 2 не показаны. В обоих типах СХД кластеров на JovianDSS можно сформировать только два пула данных, а в отдельностоящей некластеризованной СХД на базе JovianDSS такого ограничения нет. Таким образом, пулы дисков в СХД кластере можно сделать разными по производительности и отказоустойчивости, используя разные уровни RAID-Z/mirror или собрав пул только из SSD, исходя из требований к СХД от выполняемых задач.
После создания пулов на них формируются блочные и/или файловые ресурсы, причем имеется целый набор назначаемых параметров файловой системы ZFS, которые могут влиять на производительность. Блочные ресурсы – это тома zvol, которые привязываются к таргетам, и через них отдаются серверам-клиентам в SAN, а файловые ресурсы – это наборы данных dataset, на которых создаются общие папки shares, доступ к ним предоставляется клиентам в LAN. Доступ клиентов к iSCSI таргетам блочных ресурсов может быть настроен по протоколам CHAP, Mutual CHAP, только с разрешенных IP адресов или доступ может быть запрещен с указанных IP адресов. Права и политики доступа к общим папкам могут быть назначены из службы каталогов Active Directory, если в сети имеется доменная структура Microsoft Windows Server.
Режим Active –Active в Metro и стандартном кластерах
И стандартный и Metro кластеры могут работать в режиме Active–Active, т.е. когда оба узла кластера активны и одновременно обеспечивают доступ к данным, что эффективнее использует оборудование и значительно повышает производительность кластерной СХД. Для работы в режиме Active–Active пулы данных должны «размещаться» на разных узлах кластера, т.е. доступ к разным пулам производится через разные узлы. В случае сбоя/аварии на одном из узлов СХД кластера, пул данных, доступ к которому предоставлялся через этот узел, «импортируется» другим узлом кластера и становится доступен клиентам СХД через оставшийся в работе узел, как это показано на Картинке 3.

Картинка 3 Переход пула при отказе узла в Metro и стандартном кластерах
Каждому пулу данных в кластере присваивается один или несколько виртуальных IP адресов, чтобы в случае «перехода» пула с отказавшего узла на другой узел, у клиентов СХД сохранялся доступ к данным пула по тем же самым виртуальным IP адресам. Клиенты Metro кластера, как и клиенты стандартного кластера, должны иметь сетевой доступ к обоим узлам кластера СХД.
Интерфейсы в Metro и стандартном кластерах
Интерфейсы кластеров СХД в JovianDSS можно разделить на несколько групп, исходя из их назначения. Это пути доступа клиентов - access path, кластерное кольцо - cluster path и путь зеркалирования - mirror path, который нужен только в Metro кластере.
 Картинка 4 Интерфейсы в Metro кластерах
Картинка 4 Интерфейсы в Metro кластерах
У каждого из узлов СХД кластера часть интерфейсов предназначена для доступа клиентов. Их можно назвать file access path и block access path – файловый и блочный пути доступа. По этим интерфейсам к СХД могут обращаться, как рабочие станции по файловым протоколам SMB/NFS из локальной сети LAN, так и хост-серверы по блочным протоколам iSCSI/Fibre Channel из сети хранения данных SAN.
Пути file access path и block access path для iSCSI могут быть организованы на одних и тех же физических Ethernet портах сетевых адаптеров узлов кластера или каждому из путей можно выделить свои порты. Так как в качестве аппаратной платформы для СХД на базе ПО Open-E JovianDSS мы сами выбираем стандартное серверное оборудование, то есть возможность установить на каждом узле кластера СХД необходимое для конкретной задачи количество сетевых или FC адаптеров. Для увеличения пропускной способности доступа к СХД можно использовать несколько физических интерфейсов, но важно учитывать, что для файловых и для блочных протоколов доступа расширение полосы пропускания достигается разными способами.
file access path Для ускорения и отказоустойчивости файлового доступа к общим папкам в LAN - file access path, на каждом из узлов СХД кластера применяется объедение в единый логический интерфейс bond нескольких физических портов сетевых Ethernet адаптеров. Этому bond интерфейсу указывается режим работы и присваивается IP адрес. Open-E JovianDSS позволяет выбрать один из семи различных режимов работы такого агрегированного bond интерфейса. Встроенная справка (значок «?» в окне веб интерфейса) JovianDSS дает описание каждого из них, см. ниже (картинка крупнее по клику на ней):

Так, например, bond интерфейс в режиме balance-rr (round-robin) будет последовательно передавать пакеты данных по каждому из объединенных в агрегированный канал портов сетевых адаптеров, что и балансирует нагрузку и обеспечивает отказоустойчивость. В режиме active-backup лишь один порт из сетевых адаптеров объединенного bond интерфейса активен, а остальные находятся в ожидании, и один из них включается в работу только в случае сбоя активного сетевого адаптера. Все сетевые адаптеры Ethernet объединяемые в bond интерфейс должны быть настроены на одну и ту же скорость работы и должен быть включен полнодуплексный режим. Рекомендуется объединять в bond адаптеры одного производителя и на одном и том же чипсете. Обычно клиенты СХД кластера, которым предоставляется доступ к данным по файловым протоколам, подключаются к узлам СХД через сетевые коммутаторы, поэтому агрегированные bond интерфейсы узлов СХД должны распознаваться и со стороны Ethernet коммутаторов. Здесь необходимо учитывать особенности работы bond в разных режимах. Например, bond в режиме balance-rr должен подключаться к одному коммутатору (он может быть и логический - составленный из объединённых в стек физических коммутаторов, чтобы избежать единой точки отказа), а вот для bond интерфейса в режиме active-backup, такого ограничения нет и т.д.
Увеличение пропускной способности доступа к СХД по bond интерфейсам будет лишь в случае одновременной работы нескольких разных клиентов по файловым протоколам. Если всего один клиент обращается к общим папкам хранилища по bond интерфейсу в режиме balance-rr из 4х сетевых Ethernet портов, то обмен данными будет производиться всего по одному физическому порту. А вот 4 и более разных клиентов смогут одновременно работать с файлами по такому bond интерфейсу с СХД намного быстрее, чем по одному физическому порту Ethernet адаптера.
block access path Для доступа серверов к кластеру СХД по блочному протоколу iSCSI - block access path использование агрегированного bond интерфейса обычно не имеют смысла (кроме повышения отказоустойчивости), т.к. это не дает увеличения в пропускной способности канала доступа серверов к СХД. Для ускорения доступа здесь используется технология многопутевого доступа или multipathing I/O, сокращенно MPIO. Сервер с несколькими сетевыми портами в SAN получает доступ к ресурсам хранилища не по одному, а, например, по двум путям одновременно, что и увеличивает полосу доступа двое. Для доступа ISCSI MPIO по двум путям, необходимо, чтобы каждый из двух Ethernet портов хост сервера клиента работал в разных подсетях, и каждый порт подключался к «своему» виртуальному IP адресу на одном пуле данных в СХД кластере. Обратите внимание, что со стороны СХД кластера клиентам SAN предоставляются только пути доступа, но не указывается режим работы MPIO. Режим работы путей MPIO может быть выбран на сервере клиенте. Например, в Windows Server 2016, где компонент MPIO не ставится в системе по умолчанию, настройку MPIO можно выполнить через графический интерфейс или через Powershell. По умолчанию для MPIO используется политика балансировки нагрузки round robin, но ее можно изменить, например, на только отказоустойчивый режим Fail Over Only. Разумеется, если пути MPIO доступа настроены на работу только в отказоустойчивом режиме, то увеличения полосы пропускания и ускорения блочного доступа к кластеру СХД не будет. Управлять режимом работы MPIO можно средствами виртуальной среды, если узел СХД JovianDSS установлен в виртуальной машине.
cluster path Для взаимодействия узлов кластера между собой и отслеживания состояний узлов предназначены интерфейсы кластерного пути cluster path, иногда называемые кольцом ring. По этому пути узлы кластера могут слышать heartbeat «сердцебиение» друг друга, и отслеживать ситуации сбоя/отказа узла, чтобы перевести ресурсы хранения данных на оставшийся в работе узел. Для кольца необходима частная подсеть, в которой кроме обоих узлов кластера должны быть еще не менее двух пинг узлов ping nodes – устройств, которые отвечают на команды ping периодически отправляемые с каждого из узлов кластера. В качестве пинг узлов могут быть и Ethernet коммутаторы и не выключаемые клиенты сети. Дело в том, что для начала перевода ресурсов с узла на узел недостаточно только пропадания сигнала heartbeat между узлами. Возможна ситуация, когда heartbeat в порядке, но клиенты не получают доступ к ресурсам одного из узлов из-за сбоя в сети. В этом случае один из узлов не будет получать ответов от пинг узлов, что и будет являться поводом для кластера СХД начать перевод ресурсов на оставшийся доступным для клиентов узел. Необходимо при настройке кластера указывать не менее двух пинг узлов, чтобы исключить переход ресурсов при сбое на самом пинг узле. В целях отказоустойчивости для кольца cluster path используется bond интерфейс из двух физических Ethernet адаптеров в режиме active backup. Для JovianDSS Open-E предоставляет по запросу small update (дополнительный программный компонент), который позволяет работать и с одним линком в cluster path, что удобно при тестировании, но такая конфигурация категорически не рекомендуется для производственных кластерных СХД из-за снижения отказоустойчивости. Высоких требований по пропускной способности для cluster path нет, и поэтому часто то из этой же подсети осуществляется доступ к веб интерфейсу управления СХД. Веб интерфейс управления СХД доступен по cluster path или по acess path.
mirror path Для работы стандартного кластера всех указанных выше интерфейсов на узлах СХД кластера достаточно, но для Metro кластера нужен еще и путь для зеркалирования mirror path, через который производится синхронизация данных между дисковыми хранилищами обоих узлов. Это должен быть высокоскоростной Ethernet интерфейс. Рекомендуется не менее 10GE и подключение точка-точка, чтобы исключить задержки при коммутации. Длина линка при подключении точка-точка может составлять до 80 км, а при использовании промежуточных коммутаторов и более, что в условиях городской вычислительной сети MAN достижимо при использовании «темных» волокон оптического кабеля. Важно, чтобы выдерживалось требование JovianDSS - задержка при работе по интерфейсу mirror path не должна превышать 5 миллисекунд. Под задержкой подразумевается круговая задержка, т.е. время, затраченное на отправку сигнала, плюс время необходимое для получения подтверждения приема сигнала - Round Trip Time (RTT). Именно эта задержка и показывается в миллисекундах при использовании команды ping, что позволяет легко ее определить. Для увеличения полосы пропускания и повышения отказоустойчивости mirror path можно построить из нескольких портов как агрегированный bond интерфейс в режиме round robin с балансировкой нагрузки.
Примеры схем подключений к Metro кластеру
Теперь, понимая назначение и организацию всех подключений, мы можем разобраться в примерах различных схем Metro кластера, которые представлены на сайте Open-E внизу страницы. Таких схем приводится 4 штуки, т.к. все они оптимальны для различных задач. Обратите внимание, что на всех представленных схемах cluster path создана из двух сетевых портов, объединенных в bond в режиме active backup.
Все показанные ниже картинки являются собственностью компании Open-E и публикуются здесь с разрешения Open-E и со ссылкой (по клику) на их оригинальное размещение.
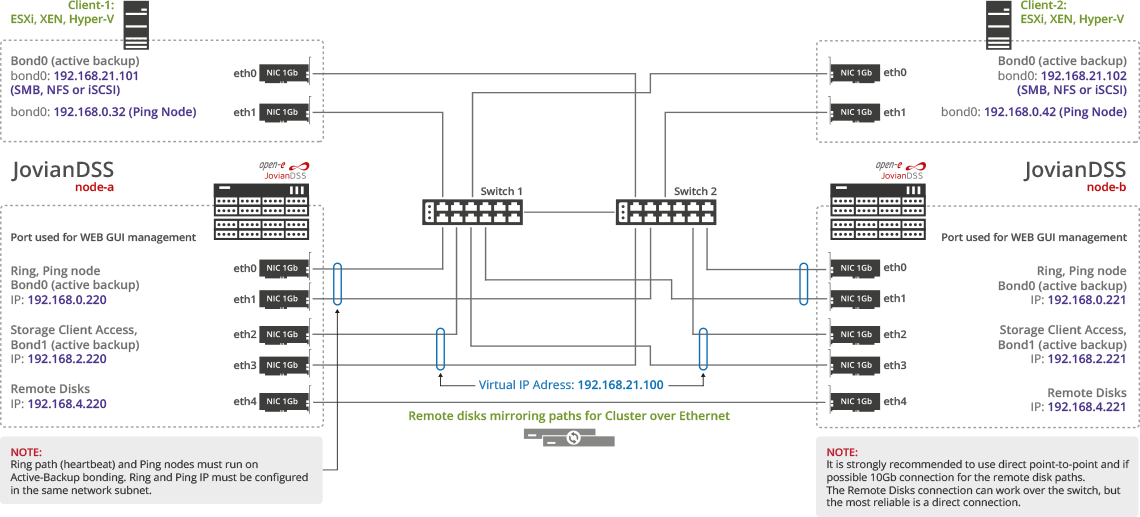
Схема 1 - Файловый доступ file access path для клиентов ЛВС к общим папкам дискового хранилища выполнен как агрегированный bond интерфейс в режиме active backup. Это НЕ позволяет увеличить полосу пропускания для файлового доступа для нескольких клиентов, но повышает отказоустойчивость. Доступ по iSCSI через block access path организован лишь по одному пути без MPIO.
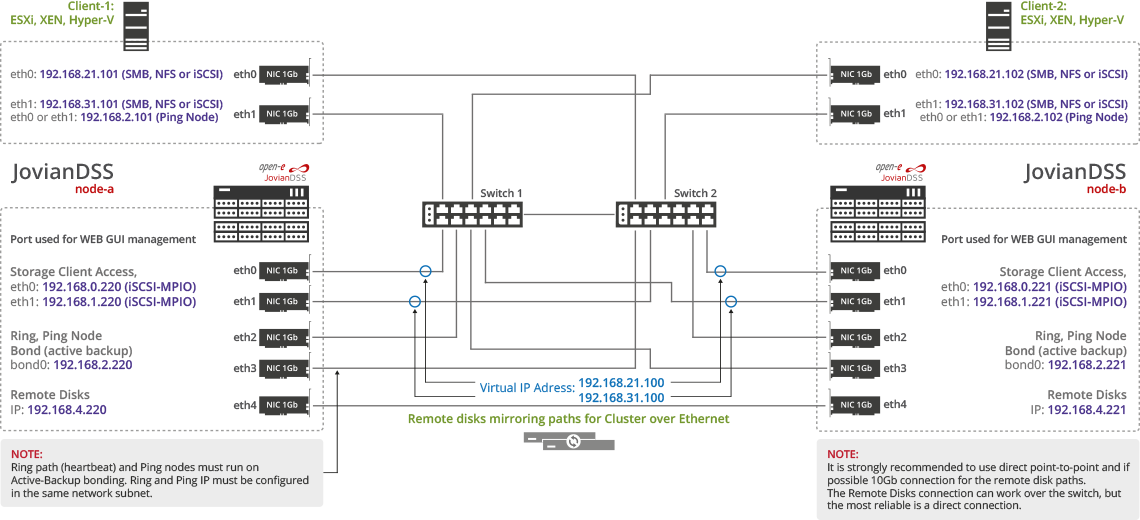
Схема 2 - Блочный доступ block access path для серверов из SAN по iSCSI производится по двум путямчерез MPIO, что позволяет увеличить полосу пропускания, в случае, если MPIO на серверах клиентах настроен как round robin. Файловый доступ file access path для клиентов ЛВС организован без bond, т.о. полоса пропускания файлового доступа для нескольких клиентов будет такой же, как и для одного клиента LAN.
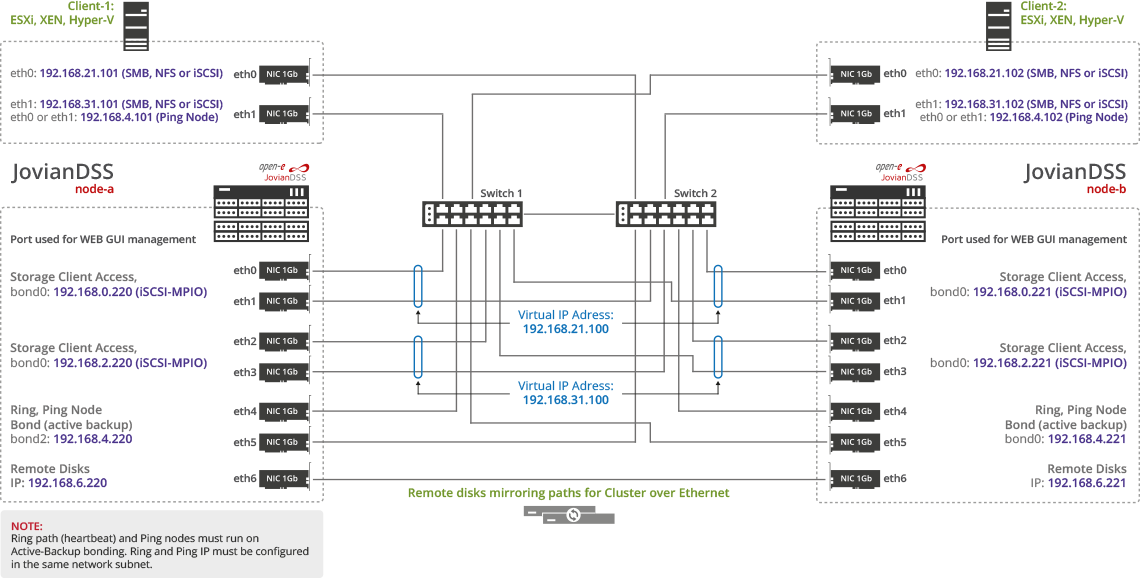
Схема 3 - Оптимальна для унифицированной кластеризованной СХД и с файловым и с блочным доступом. Клиенты ЛВС по file access path получают доступ к общим папкам через bond, а серверы сети хранения данных SAN получают многопутевый доступ MPIO.
Полагаю, что теперь разобраться со Схемой 4 уже не составит труда. К ее особенностям стоит отнести лишь то, что путь зеркалирования дисковых хранилищ mirror path реализован как bond интерфейс в режиме balance-rr (round-robin), чего не было в Схемах 1-3.
Вспомним, что так как мы можем сами выбирать стандартное серверное оборудование для узлов СХД кластера на JovianDSS, то не будет проблемой установить столько сетевых адаптеров, сколько необходимо для реализации той или иной схемы как стандартного, так и Metro кластера.
Split-Brain в Metro кластере
 Почему нужно и mirror path и cluster path делать в Metro кластере отказоустойчивыми? Это действительно важно, т.к. при отказах или сбоях в этих служебных путях кластера возможна очень неприятная ситуация, которую называют Split-Brain - «раздвоение мозга». Причем эта проблема не может появиться в стандартном кластере СХД с общим дисковым хранилищем, она характерна только для Metro кластеров СХД, где есть двойное дисковое хранилище и mirror path.
Почему нужно и mirror path и cluster path делать в Metro кластере отказоустойчивыми? Это действительно важно, т.к. при отказах или сбоях в этих служебных путях кластера возможна очень неприятная ситуация, которую называют Split-Brain - «раздвоение мозга». Причем эта проблема не может появиться в стандартном кластере СХД с общим дисковым хранилищем, она характерна только для Metro кластеров СХД, где есть двойное дисковое хранилище и mirror path.
Пусть Metro кластер СХД работает в обычном режиме и узел А предоставляет клиентам доступ по виртуальному IP адресу к пулу 0, а узел Б, в свою очередь, предоставляет доступ по другому виртуальному IP адресу к пулу 1. При аварии и выходе из строя, скажем узла Б, данные пула 1 «импортируются», т.е. становятся доступными клиентам по тем же самым виртуальным IP адресам, но через узел А - этим и обеспечивается отказоустойчивость в СХД кластере. При этом, на каждом узле Metro кластера в дисковых хранилищах физически находятся данные и пула 0 и пула 1, синхронизированные между узлами по mirror path. Теперь допустим, что произошел отказ интерфейса mirror path, и узлы A и Б больше не могут синхронизовать данные пулов. Доступ клиентов к пулам данным на обоих узлах продолжается, и в процессе работы они изменяют данные на пулах 0 и 1. Но при этом данные пула 0 и 1 на узле А станут отличаться от их зеркал на узле Б. Эта ситуация и получила название split brain в Metro кластере. Работа клиентов с Metro кластером СХД у которого «раздвоением мозга» может продолжаться без проблем, но лишь до тех пор, пока не случится еще один из нижеследующих сбоев:
- сбой в интерфейсе кольца cluster path, что вызовет у каждого из узлов «впечатление», что соседний узел вышел из строя и нужно предоставить клиентам пул данных, который до сбоя предоставлялся через отказавший узел. Это приведет к тому, что каждый из узлов предоставит оба пула данных клиентам, но данные на одних и тех же пулах у разных узлов будут разными.
- сбой одного из узлов кластера. После чего пул отказавшего узла будет предоставлен клиентам через оставшийся другой узел, где уже данные этого пула отличаются от актуальных.
Разумеется, в этом примере считалось, что в Metro кластере нет встроенной защиты на случай таких ситуаций.
В Metro кластере СХД на Open-E JovianDSS постоянно отслеживается состояние mirror path, и в случае сбоя зеркалирования, кластер переходит в особое состояние, при котором узлы будут предоставлять доступ к данным только через пулы, которыми они управляют, и не будут импортировать пулы другого узла, до тех пор, пока связь по mirror path не будет восстановлена и данные автоматически не синхронизируются.Если в Metro кластере произошел отказ cluster path, а зеркалирование данных по mirror path продолжается, то действует другой встроенный механизм, который не позволит каждому узлу решить, что сосед вышел из строя, и предоставить пул сбойного узла клиентам. Узлы Metro кластера JovianDSS один раз в секунду производят короткие записи временных меток на диски того пула, который они предоставляют клиентам, и эти метки синхронизируются между узлами по mirror path. Тем самым, по наличию такого «тиканья» можно выяснить, какой из пулов контролируется каким узлом кластера, даже при отказе cluster path. Каждый из узлов, прежде, чем начать импортировать пул и предоставлять доступ к нему клиентов, проверяет временные метки его дисков. Если там обнаружены временные метки от другого узла не старее 10 секунд, то доступ к этому пулу клиентам узел предоставлять не будет, что исключает split brain.
При одновременном отказе интерфейсов и mirror path и cluster path, т.е. полной потере связи между узлами, оба узла Metro кластера перейдут в режим separated (раздельное состояние), и продолжат предоставлять доступ к данным только через те пулы, которыми они управляли до потери связей. В данном случае, после восстановления обеих связей, уже не произойдет автоматическое воссоединение узлов в кластере, и потребуются действия системного администратора, чтобы снова перевести кластер в начальное отказоустойчивое состояние с корректными данными.
Именно поэтому, чтобы избежать последней ситуации с переходом кластера в режим separated, и временного перебоя в отказоустойчивости кластера в ожидании пока системный администратор ее восстановит, формируют как mirror path, так и cluster path в виде отказоустойчивых bond интерфейсов. Важно отметить, что любом случае, сбои компонентов, приводящие Metro кластер JovianDSS к split brain, не приводят к потере данных.
Защита данных в Metro кластере
 В статье «Защита данных в СХД на базе ПО Open-E JovianDSS» в Таблице 1 были перечислены угрозы данным и представлены схемы построения СХД с различной степенью защиты. Наивысший уровень защиты при минимальных затратах давала схема Уровня 5 - стандартный кластер СХД на одной площадке и отдельная СХД для репликации данных на удаленной площадке.
В статье «Защита данных в СХД на базе ПО Open-E JovianDSS» в Таблице 1 были перечислены угрозы данным и представлены схемы построения СХД с различной степенью защиты. Наивысший уровень защиты при минимальных затратах давала схема Уровня 5 - стандартный кластер СХД на одной площадке и отдельная СХД для репликации данных на удаленной площадке.
Metro кластер JovianDSS обеспечивает полную защиту данных от всех перечисленных угроз (см. таблицу слева) при использовании встроенной репликации моментальных снимков с ресурсов одного пула на другой пул кластера. Для конфигураций, где необходим высочайший уровень защиты данных, можно к Metro кластеру добавить еще и отдельную некластерную СХД на JovianDSS, где будут храниться дополнительные моментальные снимки с обоих пулов данных Metro кластера.
Лицензирование в Metro и стандартном кластерах
Лицензирование стандартного и Metro кластеров на базе Open-E JovianDSS похоже и отличается незначительно. В обоих случаях необходимы следующие 4 пункта лицензий:
1. 1785 Open-E JovianDSS базовая 0 ТБ – 2 шт. (на каждый узел кластера)
2. 1818 Open-E JovianDSS на пакет компонентов HA кластер – 1 шт. (на оба узла кластера Стандарт)
1851 Open-E JovianDSS на пакет компонентов Metro кластер – 1 шт. (на оба узла кластера Metro)
3. XXXX Open-E JovianDSS на расширение объема на х ТБ – 1 шт. (на оба узла кластера Стандарт)
XXXX Open-E JovianDSS на расширение объема на х ТБ – 2 шт. (на каждый узел кластера Metro)
4. XXXX Open JovianDSS на x лет, вид поддержки, объем ТБ – 2 шт. (на каждый узел кластера)
Кроме пункта 2, где указывается собственно тип кластера, важное отличие есть в количестве лицензий на объем дискового хранилища в пункте 3. Для Metro кластера с двойным хранилищем нужны 2 лицензии XXXX на расширение объема, а в стандартном кластере в общим хранилищем достаточно одной такой лицензии. При больших объемах хранения, и с учетом того, что лицензия 1851 дороже, чем 1818, стоимость всех лицензий для Metro кластера становится заметно выше, чем для стандартного кластера. Стоимость лицензий технической поддержки зависит от объема дискового хранилища кластера: 4- 16ТБ, 20-128ТБ, 132-512ТБ и более 512ТБ, типа поддержки: Стандарт, Премиум, 24/7 и срока действия: 1, 3 и 5 лет. Рекомендуется для производственного кластера СХД выбирать поддержку Премиум на 3 года. Интересно, что, купив лицензию 1851 на Metro кластер, вы получаете право использовать ее и для построения стандартного кластера, но при этом лицензируемый объем будет ограничен объемом лишь одного из дисковых хранилищ имеющегося Metro кластера. В лицензировании кластеров на базе Open-E JovianDSS есть много нюансов, обратитесь в наш отдел лицензирования, и мы подберем оптимальную для вас вариант-схему.
Metro и стандартные кластеры СХД на Open-E JovianDSS - решения для любого бизнеса
Для создания Metro кластера, кроме более дорогих лицензий, потребуется больше «железа» в сравнении со стандартным кластером, т.к. нужно и второе дисковое хранилище, и дорогие дальнобойные интерфейсы связи узлов. Но вообще-то, все представленные на ИТ рынке Metro кластеры СХД - это класс решений только корпоративного уровня. Такие решения, как правило, недоступны небольшим компаниям из-за своей высокой стоимости и привязаны к проприетарным аппаратным СХД с ограниченной гибкостью по модернизации.
Программно-определяемые СХД на базе ПО Open-E JovianDSS позволяют строить Metro кластеры по весьма доступной цене за счет высочайшей ценовой эффективности решений. Использование стандартного серверного оборудования, подбор его под нужные характеристики производительности и простота модернизации при необходимости (Open-E JovianDSS позволяет заменять устаревшее оборудование, сохранив лицензии JovianDSS) значительно расширяют круг компаний, которые могут позволить применение Metro кластеров для своих задач. При этом они получают сразу без скрытых дополнительных затрат весь мощный функционал хранилищ данных, входящий в стоимость лицензий Open-E JovianDSS, включая: динамическое кэширование, резервное копирование с мгновенным восстановлением, неограниченное количество моментальных снимков и клонов данных, работу в виртуальной среде и многое другое. Подробнее об этом здесь.
На сайте Open-E имеется 60-ти дневная полнофункциональная, включая оба вида кластеров, пробная версия ПО Open-E JovianDSS. Обширный список совместимости со стандартным серверным «железом» и возможность работы в VM среде, позволяют потенциальным заказчикам перед покупкой реально оценить, как производительность, так и функционал получаемых кластерных СХД на базе Open-E JovianDSS. В проведении тестирования помогут пошаговые руководства по настройке Metro и стандартного кластеров, учебные видео материалы по JovianDSS и записи вебинаров по кластерам СХД.
И, конечно же, при проведении тестирования всегда можно обратиться за поддержкой в техническую лабораторию ГК «ВИСТ». Наши квалифицированные инженеры всегда помогут в выборе оптимального технического решения, а также могут на нужное время поделиться тестовым оборудованием.
Для получения дополнительной информации, пожалуйста, обращайтесь в наш отдел продаж.
© Александр Матвеев, 2018 Этот адрес электронной почты защищен от спам-ботов. У вас должен быть включен JavaScript для просмотра.
директор по развитию бизнеса ООО «Вист СПб»
При перепечатке и использовании этого материала
указание авторства (Александр Матвеев, 2018)
и ссылка на источник (www.vist-spb.ru) обязательны.
Похожие материалы:
Более новые статьи:
Более старые статьи:
- Защита данных в СХД на базе ПО Open-E JovianDSS - 28/08/2018 12:33
- Что диск грядущий нам готовит или жесткие диски большого объема в RAID уровней 5 и 6 - 09/04/2018 15:25
- Расширенная гарантия Intel на серверные компоненты - 30/01/2018 17:04
- Дисковая NVMe подсистема серверов на платформе Intel Purley - 26/09/2017 14:40
- Монтажные шкафы с активным подавлением шума VIST AcoustiRACK powered by Silentium - 18/07/2017 10:34